Cardboard Haberdashery
The annual Venice Mardi Gras parade was on the 25th (due to scheduling issues, that’s the midst of Lent this year!), so it was time to make a costume.
As the self-appointed official unofficial photographer, I always need to be able to wield one or more cameras, so my costumes tend to focus on some kind of headgear that won’t get in the way. Past costumes have included wild structures to hide a fill-in flash, wizard hats, a big papier-mâché fish, and the like. This year, since the theme is “Magical Mystery Trip,” I figured a variant on a top-hat would hint at magicianishness. A magical geometrical figure adds to the alchemical implications, so I put a Mardi Gras themed dodecahedron on it.
The top hat itself is made of cardboard. I started by measuring my head with a piece of string, cutting out a sheet from a delivery box (the corrugations pulled over the hard edge of the table to make it flexible), and creating a cylinder. Duct tape was used inside to hold it together. A top plug was hand-drawn, cut out, and hot-glued into place. Oh, so much hot glue. It’s great for imprecise work like this: it fills gaps, is adjustable for those vital few seconds, but hardens quickly into a pretty good secure bond. The brim was then drawn onto a sheet of chipboard, cut, positioned, and glued. After that, I cut the cylinder down to the curve with a razor blade, and taped in some padding with gaffer tape to help smooth that edge.



Then the hat part got put aside for a bit while the decoration was implemented. A dodecahedron is a geometric solid made of twelve pentagons. To add interest, I used Affinity Designer to illustrate a collection of pentagonal patterns based on fleurs-de-lis. You can download the design file as a PDF.
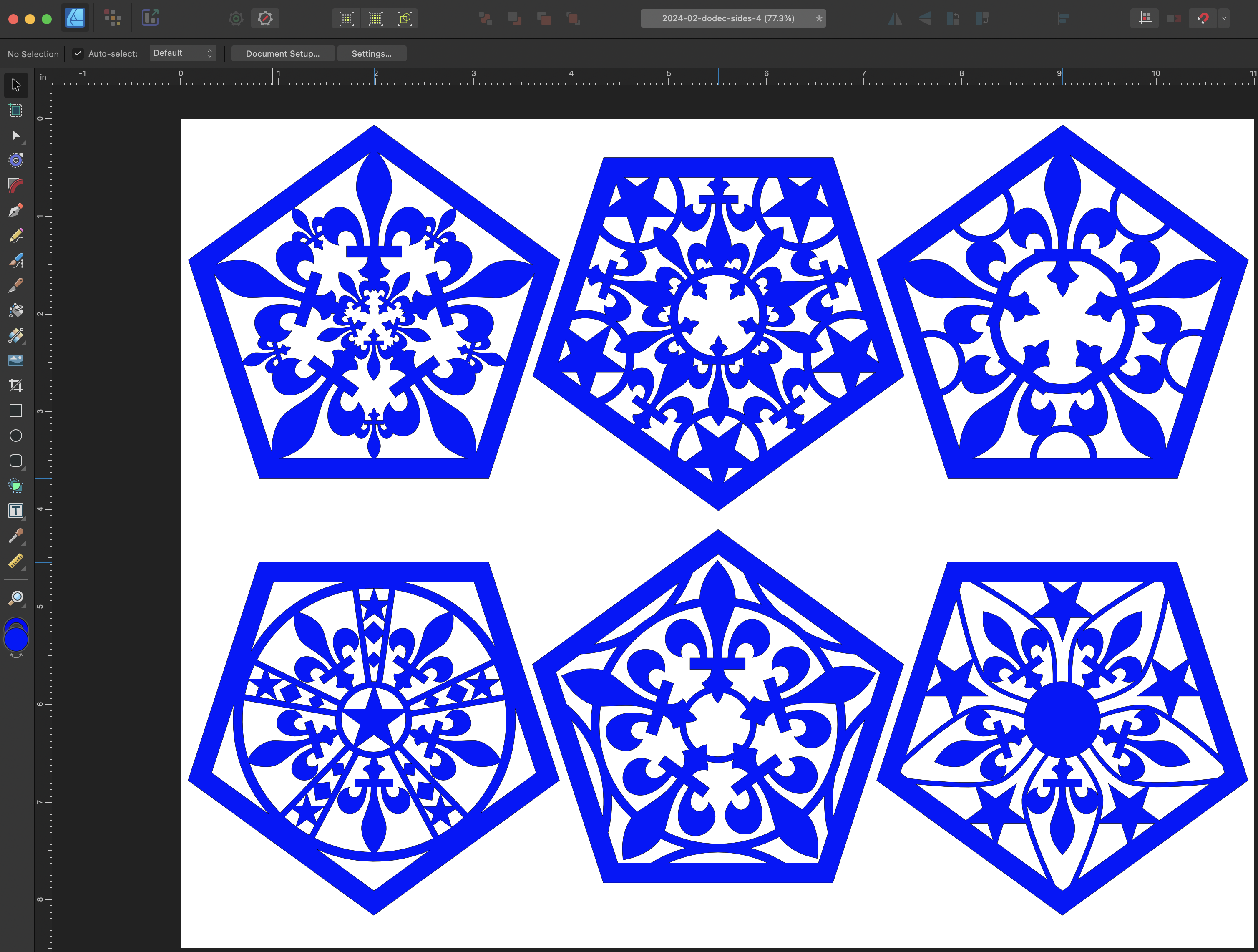
I took the file and a pack of acid-free chipboard to CrashSpace, and zapped out a bunch of pentagons on the trusty Epilog laser cutter. The chipboard comes in sheets that are 12 by 12 inches and “medium weight” which translates to 0.057 inches (~1.47mm) thick. Because the boards are not perfectly flat, the laser cutter doesn’t cut exactly the same across the entire sheet, meaning that some of the cut-out areas aren’t completely cut out.
In the vinyl- and paper-cutting crafts world, they refer to removing the cut-out portions from a design with the delightful term “weeding.” For most of the patterns, weeding just involves popping out the loosely connected portions. But there are places where I got poor through-cut. Also, the density of the chipboard is not very uniform, so some areas took a lot of cleanup with an X-Acto knife.



If I had been wiser, I would have recut these at a slightly slower speed to make sure there was complete cut-through.
Then, out came the hot-glue again, and the pentagons were assembled into a dodecahedron. You can kind of see in the lower left corner of picture below a temporary jig I made for positioning the pentagons into groups of three for rapid gluing. It’s not very precise, but fortunately it doesn’t need to be.

Next came painting. I have a set of metallic acrylic paints that were bought for last year’s Mardi Gras mask. In retrospect, I should not have bought them as the “metallic” effect is produced by tiny plastic flakes like glitter. Ugh. Micro-plastics. We’re all full of ’em, and it’s only getting worse. But I already have the paints, so I decided to use them.



The final result didn’t end up looking half bad. I wore a not-terribly-clashing floral front-plate for my FloMask to complete the look.






In the spirit of Mardi Gras, at the end of the parade, the hat was given to a school teacher whose students had just learned about dodecahedrons.












